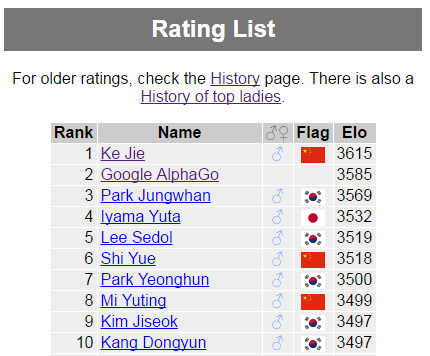
หลายท่านคงได้ทราบผลการแข่งโกะ (หมากล้อม) ระหว่าง AlphaGO กับ Lee Sedol ทำให้ขึ้นมาเป็นอันดับสองของโลก รองจาก Ke Jie โดยคำนวจจาก Elo (https://en.wikipedia.org/wiki/Elo_rating_system)

รูปจาก http://www.goratings.org/
ผมว่าต้องมีหลายท่านที่เริ่มสนใจ AlphaGO มากขึ้นแล้วซินะครับ เราลองมาดูประวัติกันซักหน่อยว่ากว่าจะมาเป็น AlphaGO เค้าเริ่มต้นจาก Google DeepMind จากบริษัท British artificial intelligence ก่อตั้งเมื่อ เดือนกันยายน ปี 2010 หลังจากนั้นถูกควบกิจการโดย Google ในปี 2014 โดยมุ่งเน้นสร้างระบบเรียนรู้การเล่นเกมส์ เพื่อให้เทียบเท่ามนุษย์ จนกระทั้งเดือน ตุลาคม ปี 2015 สร้างโปรแกรมสำหรับเล่นหมากล้อมสำเร็จ ทดสอบครั้งแรกกับแชมป์ European หมากล้อม Fan Hui 2 ดั้ง โดย AlphaGo ชนะ 5 กระดาน โดยไม่แพ้ หลังจากนั้นได้แข่งกับ Lee Sedol 9 ดั้ง โดย AlphaGo ชนะ 4 กระดาน แพ้ 1 กระดาน
การทำงานของ Alpha Go ใช้อัลกอริทึมร่วมกัน ระหว่าง Neural Networks, Machine Learning และ Monte Carlo tree search อ่านเพิ่มได้ที่ https://gogameguru.com/i/2016/03/deepmind-mastering-go.pdf
การทำงานส่วน Neural Networks (NN) หรือโครงข่ายประสาทเทียม
1. สอน : NN ได้รับการป้อนบันทึกหมากจำนวน 30 ล้านตาเดิน จาก KGS Go Server แล้วให้พยายาม “เดา” หมากเม็ดถัดไปที่จะเดินลงมา NN ในขั้นนี้มี 2 ตัว คือ Supervised Learning (SL) Policy และ Rollout Policy ซึ่งเหมือนกันทุกอย่างต่างกันตรงเวลาคิด SL Policy ใช้เวลาหาคำตอบ 3 Millisecond ส่วน Rollout ใช้ 2 Microsecond แต่ความแม่นก็ต่างกันครึ่งต่อครึ่ง)
2. ซ้อม : เอา SL Policy จากขั้นตอนแรก มาแข่งกับตัวมันเอง (ในเวอร์ชั่นก่อนๆ) จนได้ข้อมูลมาอีก 30 ล้านตาเดินแล้วให้คะแนน ถ้าตาเดินนั้นทำให้ชนะ ผลที่ได้จากขั้นตอนนี้เรียกว่า Reinforcement Learning (RL) Policy กูเกิลบอกว่า RL Policy ชนะ SL Policy ได้มากกว่า 80% และลำพัง RL Policy ก็เพียงพอจะชนะโปรแกรมโกะอื่นๆในโลกมากกว่า 85%
3. สังเคราะห์ : เพื่อให้การตัดสินใจกว้างขึ้น กูเกิลตัดสินใจสร้าง NN ขึ้นอีกหนึ่งตัวที่ให้คำตอบเป็นความน่าจะเป็นที่จะชนะของการลงหมากในแต่ละตำแหน่ง (Probability to win) NN ตัวนี้ได้จากตำแหน่งหมากเวลาใดๆ เทียบกับผลลัพธ์สุดท้ายว่าเกมส์นั้นชนะหรือแพ้ ข้อมูลที่ใช้ได้จากการใช้ RL Policy แข่งกับตัวมันเอง อีก 30 ล้านตาเดิน เรียกว่า Value Networks

การเลือกที่ลงด้วย Monti Carlo Tree Search (MCTS) เทคนิค

1. จากภาพโปรแกรมจะเริ่มจากการกวาดตากว้างๆ หนึ่งรอบประเมินตาเดินทั้งหมดที่เป็นไปได้ ขั้นตอนนี้ใช้ SL Policy (ถ้าเป็นโปรจะเดินยังไง)ให้คะแนนแต่ละทางเลือก
2. เอาทางเลือกที่คะแนนดีๆ มาลองคิดต่อ โดยลองเดินตาถัดไปหลายๆ แบบ โดยใช้ทั้ง SL Policy (โปรเดิน) RL Policy (เดินเอง)
3. ให้คะแนนแต่ละทางเลือกโดยใช้ Value Networks (เดินแบบนี้มีโอกาสชนะเท่าไหร่)ควบกับ Rollout Policy (ลองเดินต่อให้จบแบบหยาบๆ)
4. ทดลองเดินต่อจากข้อสอง (คือเดาหมากถัดไปอีกชั้น) กระบวนการนี้จะวนไปเรื่อยๆ จนกว่าจะได้ผลลัพธ์ที่น่าพอใจ แล้วก็จะเลือกทางเดินที่ดีที่สุดไปใช้

• a. โปรแกรมทำการประเมินโอกาสชนะของตาเดินทั้งหมดโดยใช้ Value Policy ที่เป็นไปได้ สีเข้มคือน่าเดิน สีอ่อนคือไม่น่าเดิน ที่มีสีแดงวงไว้ คือตาเดินที่มีโอกาสสูงสุด
• b.-d. คะแนนคำนวณแต่ละตำแหน่งจาก policy ต่างๆ กัน
• e. หมากที่โดนวงไว้คือ ตาเดินที่มีความน่าจะเป็นสูงสุดที่จะชนะ
• f. คือรูปแบบการเดินที่พยากรณ์ไว้ทั้งหมดก่อนเดินตานี้ ซึ่งฟานฮุ่ย ลงหมากที่ตำแหน่ง 1 ตามที่ Alpha Go พยากรณ์ไว้
AlphaGo ใช้ CPU 48 ตัว GPU 8 ตัว ในการทำงาน
REF : https://www.facebook.com/notes/panote-saechiew/how-alpha-go-work/1340692295948067
https://www.thairobotics.com/2016/03/13/alphago-for-dummies/
https://en.wikipedia.org/wiki/AlphaGo
https://en.wikipedia.org/wiki/Convolutional_neural_network
https://en.wikipedia.org/wiki/Monte_Carlo_tree_search
https://gogameguru.com/i/2016/03/deepmind-mastering-go.pdf
https://en.wikipedia.org/wiki/Elo_rating_system














